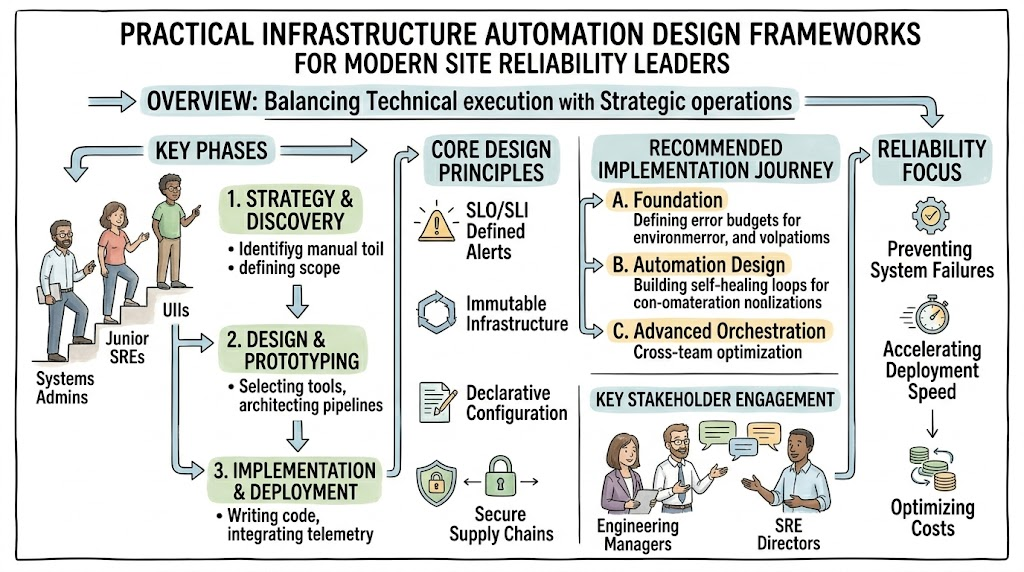
Introduction
Assembling highly resilient cloud-native infrastructure requires engineering teams to completely reshape how they handle system downtime and deployment velocity. Software leaders need a definitive framework to successfully navigate these competing priorities while scaling critical enterprise web applications. Deciding to pursue professional development in this space transforms how engineers design, automate, and govern production environments. This comprehensive handbook provides a clear architectural vision to help technology professionals make smart, data-driven decisions about their career growth. Readers can explore the structured core competencies of this operational framework by visiting the official Certified Site Reliability Manager educational program hosted by SreSchool.
What is the Certified Site Reliability Manager?
The Certified Site Reliability Manager designation delivers a rigorous, execution-first validation model for professionals managing modern cloud platforms. This specialized program focuses entirely on live production environments, pushing past static architectural theory to emphasize actionable automation. It trains candidates to write software that handles operational failure gracefully while maintaining high-velocity product delivery pipelines. By matching the actual cadences of complex enterprise development, this framework helps engineers maintain absolute platform stability during rapid software rollouts.
Who Should Pursue Certified Site Reliability Manager?
Infrastructure engineers, cloud architects, technical managers, and senior developers who oversee high-traffic distributed applications will find this curriculum incredibly useful. The coursework fits the needs of security operations teams, database specialists, and platform engineers who want to build automated reliability directly into their deployment infrastructure. Technical professionals across global markets use this validation path to gain a distinct competitive edge in the workforce. Whether an individual contributor wants to step into an architecture role or a senior director needs to reshape an enterprise operations department, this program offers immediate value.
Why Certified Site Reliability Manager is Valuable
Enterprise organizations increasingly require sophisticated reliability safeguards as distributed cloud environments grow in size and architectural complexity. This professional validation delivers lasting career leverage because it champions universal engineering principles over specific software tools or temporary vendor features. Engineers who master systematic error budget models, precise telemetry rules, and structured incident management build a highly portable skill set. This educational investment rewards candidates with superior infrastructure performance, minimized system outages, and a clear path toward executive technology roles.
Certified Site Reliability Manager Certification Overview
Professional training organizations deliver this advanced educational curriculum and evaluate student proficiency through immersive, scenario-based lab exams. Hosted on the primary learning portal, the testing environment evaluates hands-on configuration skills across real-world operational domains rather than simple term memorization. The core structure of the program ensures that an engineer can confidently debug complex system degradation while organizing cross-functional response efforts. Industry technical experts continuously update the core syllabus to match real-time shifts in enterprise infrastructure management.
Certified Site Reliability Manager Certification Tracks & Levels
The educational blueprint uses progressive skill tracks and clear experience tiers to align perfectly with individual career stages. The initial tier establishes core operational definitions and monitoring baselines, while the intermediate level introduces automated self-healing scripts and advanced cluster orchestrations. The specialized tracks explore advanced operational concepts like embedded pipeline compliance, cloud cost architecture, and massive telemetry networks. This clear path allows software professionals to step through precise learning phases as they move from basic script scripting to full system governance.
Complete Certified Site Reliability Manager Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
|---|---|---|---|---|---|
| Core Reliability Fundamentals | Foundation | Network Associates & Cloud Engineers | Linux command line basics | Telemetry collection, SLI definitions | First |
| High-Availability Automation | Professional | Senior DevOps & Platform Architects | Multi-node system deployment | Python scripting, Chaos execution | Second |
| Strategic Platform Leadership | Advanced | Engineering Directors & SRE Managers | High-level team coordination | Error budget policies, Tech hiring | Third |
Detailed Guide for Each Certified Site Reliability Manager Certification
Certified Site Reliability Manager – Foundation Level
What it is
This entry-level validation confirms an engineer's practical grasp of essential uptime metrics, baseline system monitoring, and fundamental emergency response paths within active business environments.
Who should take it
Systems administrators, QA engineers, and junior developers who want to align their daily feature code with enterprise platform uptime targets should pursue this course.
Skills you’ll gain
- Selecting appropriate Service Level Indicators for distinct user transactions
- Monitoring error budgets to determine safe weekly software release rates
- Documenting system failures accurately during post-incident review meetings
- Building clean infrastructure dashboards using open-source visualization software
Real-world projects you should be able to do
- Install monitoring daemons across a multi-tier web application architecture
- Create a detailed chronological timeline for a simulated database failure event
- Program target metrics to flag memory utilization anomalies before systems crash
Preparation plan
- 7–14 Days: Read the core architectural terminology of reliability engineering and analyze case studies focused on metrics gathering.
- 30 Days: Complete all interactive terminal labs regarding alerting structures and pass basic self-assessment quizzes.
- 60 Days: Join peer study groups, analyze historical system breakdowns, and complete full-length mock certification examinations.
Common mistakes
Many candidates fail this initial test because they memorize specific tool commands while ignoring the mathematical concepts behind service level objectives.
Best next certification after this
- Same-track option: Certified Site Reliability Manager – Professional Level
- Cross-track option: Cloud Systems Administrator
- Leadership option: Technical Infrastructure Lead
Certified Site Reliability Manager – Professional Level
What it is
This intermediate tier validates an engineer's capability to build automated recovery workflows, manage distributed telemetry pipelines, and orchestrate scalable microservices.
Who should take it
Senior DevOps practitioners, active platform engineers, and infrastructure architects who keep production cloud workloads online should take this exam.
Skills you’ll gain
- Creating automated event-driven healing scripts and dynamic resource scaling rules
- Engineering decoupled microservice patterns to prevent widespread system failures
- Managing secure container deployments across regional Kubernetes infrastructure
- Running structured fault-injection tests to locate hidden platform weaknesses
Real-world projects you should be able to do
- Construct an automated canary deployment pipeline that reads live traffic error rates to trigger rollbacks
- Execute a chaos simulation that drops network connectivity to a backup data warehouse
- Configure end-to-end distributed tracing across an enterprise application service mesh
Preparation plan
- 7–14 Days: Learn complex software resilience patterns including circuit breakers, rate limiters, and exponential backoff behaviors.
- 30 Days: Set up and test automated deployment scenarios inside an isolated cloud sandbox testing lab.
- 60 Days: Solve advanced infrastructure troubleshooting scenarios and complete comprehensive, practice evaluations.
Common mistakes
Applicants often spend too much time reading theory while failing to get enough hours of hands-on practice configuring distributed tracing tools.
Best next certification after this
- Same-track option: Certified Site Reliability Manager – Advanced Level
- Cross-track option: Advanced DevSecOps Engineer
- Leadership option: Enterprise Infrastructure Director
Certified Site Reliability Manager – Advanced Level
What it is
This executive-level validation evaluates a leader's capability to guide corporate platform strategies, balance multi-product tech budgets, and build healthy engineering cultures.
Who should take it
Technology directors, principal systems architects, and platform department managers who dictate enterprise infrastructure investments should secure this certificate.
Skills you’ll gain
- Enforcing corporate error budget restrictions across competing product engineering teams
- Breaking down technical silos through modern organizational structural design patterns
- Outlining long-term technology roadmaps that match system stability with revenue requirements
- Leading senior developers and scaling an institutional blameless post-mortem framework
Real-world projects you should be able to do
- Author an official enterprise reliability policy document that binds all product delivery teams
- Create a multi-million dollar cloud infrastructure efficiency and optimization roadmap
- Guide an entire engineering department through a structural shift from reactive operations to automated engineering
Preparation plan
- 7–14 Days: Study executive risk management strategies, corporate governance structures, and business-focused platform metrics.
- 30 Days: Read historical case studies of major infrastructure overhauls and draft sample corporate compliance rulebooks.
- 60 Days: Blend high-level management methodologies with production engineering realities to practice boardroom presentations and long-term tech planning.
Common mistakes
Candidates regularly write narrow, overly technical answers that fail to show the high-level corporate perspective required at this executive tier.
Best next certification after this
- Same-track option: Executive Technology Management Program
- Cross-track option: Corporate Cloud FinOps Director
- Leadership option: Chief Technology Officer Professional Track
Choose Your Learning Path
DevOps Path
This pathway accelerates the software engineering lifecycle by embedding automated testing frameworks and infrastructure as code tools directly into code pipelines. Engineers learn to remove manual gatekeepers from the release process, which allows development teams to ship software features without breaking production stability. This approach treats infrastructure management as a direct extension of software development, driving development velocity while maintaining perfect environment consistency.
DevSecOps Path
This strategy weaves automated security analysis and compliance checks directly into active application delivery loops. Practitioners get rid of the traditional late-stage security checkpoint bottleneck by running automated image scanning, dependency checks, and access audits during code compilation. This proactive model confirms that every software artifact satisfies corporate security guidelines before it ever deploys to an internet-facing node.
SRE Path
This technical track handles operational challenges by writing software, using engineering code to build massive, self-healing platforms. Engineers spend their days coding automated scaling solutions, defining strict service metrics, and automation out repetitive systems administration work to optimize performance. This discipline keeps highly complex distributed systems online across diverse public cloud regions despite hardware or network failures.
AIOps Path
This path uses advanced machine learning architectures to collect, process, and analyze massive volumes of real-time infrastructure logs and telemetry. Specialists learn to predict resource exhaustion points, detect subtle operational anomalies, and isolate hardware failures before standard alert thresholds even flag an issue. This practice shifts operations away from reactive fire fighting toward automated, predictive adjustments that protect customer experiences.
MLOps Path
This specialized track manages the unique deployment workflows, asset versioning rules, and monitoring needs of machine learning models inside active clusters. Data engineers and infrastructure teams collaborate to build reproducible training pipelines, track model drift anomalies, and optimize complex hardware acceleration environments. This framework brings traditional software engineering discipline to the dynamic world of artificial intelligence deployments.
DataOps Path
This specialty adapts agile software engineering mechanics and automated quality assurance checks for massive, complex enterprise data processing systems. Engineers learn to build data transformation steps as version-controlled code, preventing broken data pipelines and data corruption issues. This continuous validation approach provides analytical systems with clean, trusted data assets while minimizing processing latency.
FinOps Path
This business-centric path creates fiscal accountability across engineering departments by tracking cloud resource utilization metrics in real time. Professionals learn to audit complex cloud billing files, design cost-efficient infrastructure blueprints, and modify application architectures to maximize return on cloud investments. This methodology coordinates finance professionals, product leads, and platform developers under a single, unified budget strategy.
Role → Recommended Certified Site Reliability Manager Certifications
| Role | Recommended Certifications |
|---|---|
| DevOps Engineer | Certified Site Reliability Manager – Foundation / Professional Level |
| SRE | Certified Site Reliability Manager – Professional / Advanced Level |
| Platform Engineer | Certified Site Reliability Manager – Professional Level |
| Cloud Engineer | Certified Site Reliability Manager – Foundation Level |
| Security Engineer | Certified Site Reliability Manager – Professional Track |
| Data Engineer | Certified Site Reliability Manager – Foundation Track |
| FinOps Practitioner | Certified Site Reliability Manager – Specialized Track |
| Engineering Manager | Certified Site Reliability Manager – Advanced Level |
Next Certifications to Take After Certified Site Reliability Manager
Same Track Progression
Passing an introductory certification tier naturally positions an engineer to step into the next, deeper level of the site reliability ecosystem. Moving from the foundation group into the professional level changes your day-to-day work from defining tracking metrics to coding automated recovery scripts. Transitioning into the advanced class confirms your capacity to control large-scale corporate infrastructure departments.
Cross-Track Expansion
Adding diverse engineering disciplines to your resume prevents single-domain career stagnation and provides massive leverage during large enterprise projects. Combining an expert understanding of site reliability with automated cloud security credentials or deep cloud spending analysis creates a rare candidate profile. This horizontal technical knowledge enables engineers to lead multi-team corporate programs with absolute authority.
Leadership & Management Track
Moving completely away from manual system configuration requires specialized education in team psychology, corporate finance, and business risk assessment. Engineers who want to move into executive corporate suites should pursue targeted management tracks that highlight high-level technology governance. This structural preparation builds the business acumen required to oversee large technical organizations as a director or vice president.
Training & Certification Support Providers for Certified Site Reliability Manager
- DevOpsSchool organizes interactive training bootcamps, maintains remote sandbox environments, and builds comprehensive learning paths to help tech professionals automate continuous software delivery pipelines.
- Cotocus designs specialized corporate education workshops, creates realistic production failure drills, and provides consulting-led instruction to upskill infrastructure teams in system design.
- Scmgalaxy maintains a massive open knowledge base, configuration instruction articles, and expert-led discussion forums to help candidates pass rigorous system validation requirements.
- BestDevOps curates practical career advancement tracks, hosts real-time virtual classrooms, and develops hands-on testing sandboxes that build concrete infrastructure skills for modern tech markets.
- devsecopsschool.com provides targeted technical coursework that embeds continuous compliance scanning, automated threat hunting, and security governance rules directly into deployment code.
- sreschool.com hosts premium, dedicated education for platform engineers, delivering deep-dive masterclasses and scenario-based tests built around system availability metrics.
- aiopsschool.com instructs systems engineers on how to deploy machine learning algorithms, automated pattern matching models, and predictive telemetry tools within distributed networks.
- dataopsschool.com delivers targeted learning frameworks that apply continuous delivery workflows, automated verification checks, and structural data governance rules to big data operations.
- finopsschool.com trains technical staff on cloud financial accounting practices, demonstrating how to tune cloud infrastructure choices to optimize corporate cloud expenditures.
Frequently Asked Questions
1. Which operational metrics get the most attention during the initial foundation tier?
The training syllabus focuses heavily on configuring Service Level Objectives and Service Level Indicators to accurately measure real end-user transaction satisfaction.
2. Does this specific certification prioritize a singular cloud provider like AWS or Google Cloud?
No, the curriculum teaches completely cloud-agnostic patterns so that engineers can easily use these reliability frameworks across any private or public infrastructure.
3. What operational style does the professional examination use to evaluate a student's capacity?
The test presents a mix of complex situational engineering questions alongside live, interactive coding environments to evaluate automation skills under realistic constraints.
4. How can a system architect keep their certification current after passing the test?
The credential preserves active status for exactly three years, requiring individuals to complete educational update modules or pass a higher certification tier.
5. Can non-technical scrum masters pass these exams without learning a coding language?
While a non-programmer can clear the foundation tier, the professional exam requires real hands-on scripting knowledge to pass the automation challenges.
6. Who modifies the core learning plans when modern infrastructure engineering practices shift?
A selected committee of active principal engineers and operations directors reviews the testing parameters annually to track real-world enterprise needs.
7. Does the primary certification center support individual test registrations or just corporate cohorts?
The learning platform supports both independent industry professionals scheduling personal exams and enterprise businesses conducting structural team upskilling programs.
8. What specific advantages does this coursework offer to a veteran systems administrator?
It transforms an administrator's day-to-day focus from running manual server maintenance tasks toward engineering large-scale, automated, self-healing platforms.
9. How many study hours should a full-time engineer set aside to prepare for the professional tier?
Most successful applicants invest forty to sixty hours of focused preparation time, depending on their existing experience with container management.
10. Can students access the learning materials and sandbox labs on mobile operating systems?
The training partners maintain responsive web platforms that allow engineers to read documentation and track course progress on mobile tablets.
11. Do the advanced-level assessments require applicants to write full backend programs from scratch?
No, the advanced phase evaluates structural architecture choices, configuration debugging, framework integrations, and governance policies rather than raw software programming.
12. How does an error budget mechanism protect software developers from operational arguments?
It establishes an objective, data-driven contract that stops feature deployments when platform instability passes set limits, focusing both dev and ops on remediation.
FAQs on Certified Site Reliability Manager
1. What exact strategies do engineering leaders implement to change a traditional reactive operations group into an automated platform engineering unit?
Managers perform a comprehensive audit of all recurring manual operations to pinpoint and catalog time-consuming tasks known as toil. They commit a minimum of fifty percent of the engineering team's schedule to writing software tools that automate environment provisioning, system monitoring, and error correction. This structural shift moves staff away from reactive fire fighting, turning them into infrastructure programmers who build resilient, self-healing cloud applications.
2. How does this curriculum train tech leaders to control rising cloud infrastructure bills without degrading core application performance?
The coursework introduces precise methodologies that scale cloud compute resources up or down based on real-time user demand rather than fixed hardware configurations. Teams learn to configure automated lifecycle scripts for historical storage data, delete abandoned test environments, and optimize database resource settings. This financial framework links resource usage directly to active consumer volume, keeping infrastructure costs highly efficient.
3. What operational path should an infrastructure director enforce if a product line completely burns through its quarterly error budget allocation?
Running out of an error budget automatically activates a strict, non-negotiable pause on all new application feature deployments for that specific product line. The director focuses the development team's immediate efforts on resolving underlying code bugs, improving automated test coverage, and updating alerting rules. This guardrail protects the customer experience by ensuring that software speed never outruns the foundation platform's stability.
4. How do certified engineers architect an automated telemetry setup that isolates brief microservices errors inside large global networks?
Engineers install open-source log forwarders, performance metric collectors, and distributed tracing tools across the entire container platform layer. They attach a unique trace tracking ID to every inbound user transaction, following the exact route and response time of each internal API call. This complete system visibility allows automated monitoring scripts to isolate the specific network node causing performance drops within seconds.
5. Which guiding rules do principal engineers follow when launching a chaos engineering experiment inside an active staging environment?
Architects establish a clear, numeric baseline of standard system health metrics before injecting any intentional technical faults into the network. They select a small, carefully isolated blast radius—such as terminating a single microservice node—and check if automated self-healing scripts reroute user traffic smoothly. This test validates infrastructure resilience, revealing hidden configuration errors before an unexpected live outage strikes.
6. How does the management training help leaders resolve high-stakes priority arguments between software developers and operations teams?
The program uses the shared numeric metrics of an error budget to strip emotional bias and corporate politics out of engineering release decisions. Developers hold complete freedom to push innovative code changes as long as system stability remains within safe parameters. If platform instability threatens the error budget, the pre-established governance policy requires both teams to collaborate on system fixes immediately.
7. What distinct competencies must a security specialist master to embed compliance checks directly into automated infrastructure pipelines?
Security practitioners learn to integrate automated container vulnerability scans, software license verifications, and access privilege audits directly into continuous delivery code. They manage firewall architectures and credential access rules as version-controlled code artifacts, allowing automated testing systems to verify safety before deployment. This model stops insecure code from reaching live web servers without creating slow, manual review steps.
8. How do certified managers guide response teams through high-severity production infrastructure outages without generating panic across the company?
Leaders immediately invoke a structured incident command hierarchy that assigns clear, non-overlapping operational duties to designated engineering responders. One technical individual directs the actual diagnostic and fix effort, while a separate communication lead crafts steady status updates for business executives and affected customers. This division of labor allows developers to focus on resolving the emergency without answering constant internal status queries.
Final Thoughts: Is Certified Site Reliability Manager Worth It?
Choosing to master this technical discipline provides outstanding professional returns for anyone operating in modern cloud infrastructure environments. High-performance software businesses simply cannot afford fragile release tools or unpredictable application outages that damage consumer trust. This training eliminates temporary tool hype, focusing your attention instead on the universal engineering and management patterns that keep complex websites online. Adopting this rigorous reliability methodology clarifies your production metrics, increases development output, and establishes your professional reputation as a vital technical leader.
Top comments (0)