Introduction
Maintaining software availability while delivering updates at high velocity is a massive challenge for modern engineering teams. System downtime impacts business revenue and shakes customer trust immediately. Because of this, traditional infrastructure management is rapidly being replaced by reliability engineering principles.
The Certified Site Reliability Manager program is built to address this specific operational shift. This guide provides a detailed look into this certification roadmap, outlining how it changes technical leadership and shapes long-term career growth.
What is Certified Site Reliability Manager
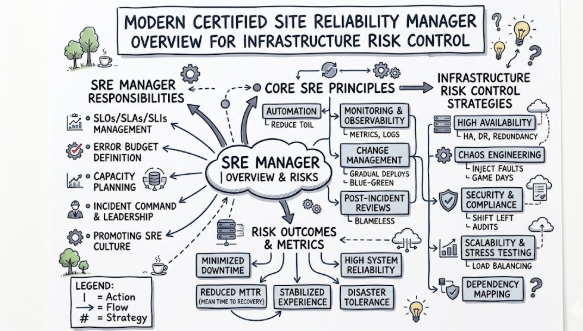
The Certified Site Reliability Manager is a professional credential focused on the operational and strategic pillars of site reliability engineering from a leadership perspective. It functions as a structured standard for professionals who oversee the health, performance, and stability of distributed systems.
This program focuses heavily on production-focused learning and real-world application rather than just theoretical concepts. It ensures that a manager can balance the need for fast feature delivery with the absolute necessity of keeping application uptime stable. It bridges the gap between low-level technical operations and high-level business objectives.
Why It Matters Today
Modern enterprises face immense pressure to keep their services running 24/7. As infrastructure shifts toward cloud-native architectures, microservices, and containers, the complexity of managing software increases. Traditional, reactive firefighting approaches no longer work.
Organizations need technical leaders who know how to manage production risks systematically. This credential matters because it teaches professionals how to build a production culture where software engineering principles are applied directly to operational problems. It transforms infrastructure management into a predictable, measurable discipline.
Why Certified Site Reliability Manager Certifications Are Important
This certification holds immense value for technical professionals for several key reasons:
- Operational Balance: It teaches you how to manage the natural tension between shipping code quickly and maintaining system uptime.
- Standardized Frameworks: It provides a common language and set of metrics to communicate infrastructure health and risks to business stakeholders.
- Toil Reduction: It helps leaders identify and eliminate repetitive manual tasks, freeing up engineering talent for high-value work.
- Career Growth: It shifts your professional positioning from a standard technical executioner to a strategic operations leader.
Why Choose SRESchool?
SRESchool is a globally recognized educational institute that focuses exclusively on reliability-centric education and site reliability engineering training. The entire curriculum is hosted on this specialized platform, ensuring that candidates access the most current, industry-relevant materials available.
Instead of relying on simple rote memorization, the platform utilizes a practical, scenario-based evaluation approach that mimics real-world production incidents. Choosing this platform ensures that you gain practical, production-focused skills that can be deployed immediately in high-pressure enterprise environments.
Certification Deep-Dive: Certified Site Reliability Manager
What Is This Certification?
This certification confirms your grasp of the essential philosophies that drive site reliability engineering from a management perspective. It validates your ability to lead teams through production-heavy workflows using structured reliability metrics and incident management frameworks.
Who Should Take This Certification?
This program is designed for working software engineers, DevOps practitioners, cloud infrastructure engineers, platform engineers, and engineering managers who intend to move into senior operational leadership roles.
Certification Overview Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
|---|---|---|---|---|---|
| Core SRE | Foundational | Aspiring Leads | Basic DevOps Knowledge | SLOs, SLIs, Toil Reduction | 1 |
| SRE Leadership | Professional | Engineering Managers | 3+ Years IT Experience | Incident Command, Hiring | 2 |
| Platform Strategy | Advanced | Directors and CTOs | Professional Level | Org Design, FinOps | 3 |
| SRE Automation | Professional | Technical Managers | Scripting Knowledge | Toil Reduction, IaC | 2 |
| Incident Mgmt | Advanced | Crisis Leads | Core SRE Knowledge | Post-mortems, Resilience | 3 |
Skills You Will Gain
- Definition and measurement of Service Level Indicators (SLIs) and Service Level Objectives (SLOs).
- Management and enforcement of Error Budgets to drive feature release decisions.
- Identification, quantification, and systematic reduction of operational toil.
- Implementation of full-stack observability and infrastructure monitoring setups.
- Coordination of incident response efforts and facilitation of blameless post-mortems.
Real-World Projects You Should Be Able to Do
- Create a centralized reliability dashboard for a microservices-based application using modern observability data.
- Draft and implement an initial Error Budget policy for an active development squad.
- Conduct a thorough manual task audit to identify and document automation opportunities within a team.
- Lead an engineering team through a simulated production outage incident as the designated Incident Commander.
- Document a comprehensive, actionable blameless post-mortem report following a system disruption.
Preparation Plan
7–14 Days Plan
Focus entirely on the official glossary, core architectural pillars, and basic definitions. Spend your time mastering basic site reliability terminology, especially the operational differences between SLIs, SLOs, and SLAs.
30 Days Plan
Complete all the foundational modules, review enterprise case studies, and complete practice exams. Practice applying metrics to sample application architectures and building simple monitoring alerts in sandbox environments.
60 Days Plan
Engage deeply with community forums, analyze large-scale infrastructure failures, and implement a full reliability roadmap in a personal sandbox project to test your organizational change strategies.
Common Mistakes to Avoid
- Ignoring the Cultural Shift: Focusing purely on software automation tools while completely skipping the cultural habits required for blameless problem-solving.
- Misdefining Metrics: Setting unrealistic SLOs that do not match actual customer needs, causing unnecessary alert fatigue for your engineering team.
- Treating Toil Separately: Allowing manual operational tasks to consume the entire schedule without dedicating real engineering time to automate them.
Best Next Certification After This
Same Track
The Professional Site Reliability Manager path is recommended to deepen your mastery over advanced incident response coordination, automated disaster recovery systems, and deep-dive latency tuning.
Cross-Track
The Certified DevOps Engineer path is ideal to broaden your knowledge across continuous integration, automated delivery pipelines, and comprehensive application lifecycle management.
Leadership / Management
The Technical Team Lead Foundation or Engineering Manager Professional track is recommended to build your organizational design, budgeting, hiring, and strategic team leadership capabilities.
Choose Your Learning Path
DevOps Path
This path is best for cloud and platform professionals who want to transition from standard automation pipelines to structured production stability. It bridges the gap between infrastructure as code and daily reliability metrics.
DevSecOps Path
This path is designed for security professionals and infrastructure engineers. It focuses on treating security vulnerabilities as technical debt that impacts long-term platform availability, embedding security checks into the operational lifecycle.
Site Reliability Engineering (SRE) Path
This path is intended for deep infrastructure specialists who want to master distributed system performance. It focuses on managing latency, traffic saturation, and microservice complexity across complex setups.
AIOps / MLOps Path
This path is built for data infrastructure engineers and machine learning professionals. It covers how to maintain the reliability and availability of the underlying systems that support automated model training and production deployments.
DataOps Path
This path is best for database administrators and data platform engineers. It focuses on applying reliability, monitoring, and automated scaling principles directly to complex data lakes and enterprise storage pipelines.
FinOps Path
This path is designed for engineering managers and financial planners. It teaches how to control and optimize cloud infrastructure spending systematically without hurting the reliability or speed of the production applications.
Role → Recommended Certifications Mapping
| Role | Recommended Certifications |
|---|---|
| DevOps Engineer | Certified Site Reliability Manager Foundational |
| Site Reliability Engineer (SRE) | CSRM Professional, Advanced Reliability Track |
| Platform Engineer | CSRM Professional, Platform Architect Track |
| Cloud Engineer | CSRM Foundational, Cloud Specialty Track |
| Security Engineer | CSRM Professional, DevSecOps Specialization |
| Data Engineer | DataOps and Reliability Foundation Track |
| FinOps Practitioner | FinOps for SRE Managers Track |
| Engineering Manager | Professional SRE Leadership Track |
Next Certifications to Take
One Same-Track Certification
The Advanced Reliability Strategy certification can be pursued to deepen your mastery over complex distributed architectures, multi-region failover automation, and corporate reliability transformations.
One Cross-Track Certification
The Certified Cloud Architect certification can be chosen to expand your technical knowledge across multi-cloud infrastructure patterns, global networking setups, and hybrid cloud integration.
One Leadership-Focused Certification
The Executive Leadership Certification can be taken to develop your skills in long-term organization design, departmental financial management, and high-level technical team alignment.
Training & Certification Support Institutions
DevOpsSchool
Comprehensive training programs and extensive learning materials are provided by this platform to support candidates preparing for various enterprise infrastructure credentials. Hands-on labs are combined with instructor-led sessions to build core technical competencies.
Cotocus
Customized corporate training programs and specialized engineering consulting services are delivered by this provider. Deep tactical instruction is offered to help production engineering teams adopt modern operational standards smoothly.
ScmGalaxy
A wide library of technical tutorials, community forums, and practice labs is maintained by this portal. Strong support is provided for professionals looking to master configuration management and automated delivery systems.
BestDevOps
Structured bootcamps and targeted learning roadmaps are offered through this educational site. Clear instruction is provided to assist engineers in migrating from legacy administration roles into automated cloud infrastructure careers.
devsecopsschool.com
Specialized training tracks that focus entirely on integrating security operations directly into automated pipelines are hosted here. Practical guidance is delivered on vulnerability scanning and compliance management.
sreschool.com
The primary platform where the official Certified Site Reliability Manager curriculum is hosted. Dedicated pathways are provided to ensure engineering professionals master production health, error budgeting, and incident resolution framework design.
aiopsschool.com
Educational materials and training courses focusing on the intersection of artificial intelligence and systems operations are provided by this site. Instruction centers on using automated insights to reduce operational noise.
dataopsschool.com
Structured learning courses centered around automated data pipeline management are delivered here. The institution helps data professionals implement consistent quality controls and infrastructure stability across large-scale storage systems.
finopsschool.com
Targeted educational tracks that address cloud financial management are hosted on this platform. Guidance is provided to help technical managers balance infrastructure operational costs directly with platform scaling needs.
FAQs Section
What is the overall difficulty level of the Certified Site Reliability Manager program?
The foundational level is built to be accessible for those with general infrastructure knowledge, while the professional and advanced tracks require deep familiarity with actual production systems and team leadership scenarios.
How much time is required to successfully prepare for the certification exam?
A preparation period spanning anywhere from 30 to 60 days is generally recommended, depending heavily on your initial hands-on experience with service level management concepts.
Are there any mandatory prerequisites before enrolling in the foundational track?
No strict certifications are required beforehand, but a basic understanding of cloud computing, software deployment pipelines, and operating system fundamentals is highly recommended.
What is the recommended certification sequence for a complete beginner?
The Core SRE Foundational track should be completed first, followed systematically by the Professional SRE Leadership track, and finally the Advanced Platform Strategy track.
What actual career value does this specific credential offer to an engineer?
Significant professional validation is achieved, helping you transition from a reactive technical role into a high-visibility, strategic engineering leadership position.
Which specific job roles can I apply for after obtaining this certification?
Eligibility is gained for competitive positions such as SRE Team Lead, Infrastructure Manager, Platform Engineering Director, and Site Reliability Manager.
Is this training framework applicable to purely on-premise data center environments?
Yes, the core principles taught—such as error budgeting, incident command, and manual toil reduction—apply universally regardless of whether the systems are cloud-hosted or physical.
How heavily does the exam test you on specific tools like Kubernetes or Terraform?
The program focuses primarily on operational strategies, management metrics, and cultural methodologies rather than testing you on the syntax of individual software tools.
Does this management track cover the financial aspects of running cloud systems?
Yes, clear modules on cloud optimization and cross-functional financial tracks are included to help leaders manage infrastructure budgets effectively.
How does this certification program address the issue of technical team burnout?
Systematic tracking and reduction of manual toil are taught, ensuring that operations engineers do not spend more than half of their time on repetitive firefighting work.
What method is used to evaluate practical skills during the certification process?
Scenario-based assessments and deep-dive enterprise case studies are utilized to measure your capacity to handle high-pressure infrastructure outages realistically.
Is there a global network available for professionals who complete the program?
Yes, an active professional ecosystem is hosted through the primary platform, allowing certified individuals to share infrastructure strategies and career opportunities globally.
Certified Site Reliability Manager
1. What makes a manager specifically an SRE manager compared to a traditional infrastructure manager?
An SRE manager applies software engineering methods directly to operational tasks and relies on strict quantitative error budgets rather than managing via subjective system checklists.
2. What is the most critical operational metric taught within this specific program?
The management of Service Level Objectives (SLOs) is emphasized as the primary driver for balancing feature deployment speed with application stability.
3. How does the CSRM framework help a leader coordinate high-pressure outage situations?
A structured Incident Command system is provided, which establishes clear ownership, separates communication channels, and ensures blameless post-mortem investigations follow every major event.
4. How does the training program help an engineering manager build an effective SRE team?
Clear frameworks covering specialized interview practices, required technical skill balances, and healthy on-call rotation designs are provided to keep engineering talent sustainable.
5. Why is cultural change highlighted so heavily throughout the site reliability manager modules?
System reliability cannot be achieved through software tools alone; a culture of blameless error reporting must be cultivated so underlying platform weaknesses can be found and fixed.
6. How are error budgets utilized by a certified manager to influence product deployment decisions?
When a service consumes its defined error budget due to outages, feature releases are paused automatically, and engineering efforts are redirected entirely toward reliability fixes.
7. Does the curriculum provide strategy templates for modern microservices architectures?
Yes, specific blueprints regarding distributed system metrics, latency monitoring, and dependency mapping are included to help handle complex cloud-native architectures.
8. What is the role of automation within the Certified Site Reliability Manager framework?
Automation is treated as the primary tool used to eliminate recurring manual operational tasks, transforming manual operations into highly scalable software solutions.
Testimonials
Amit
The structural metrics taught in this program helped me design a clear monitoring dashboard for our core microservices. System visibility was vastly improved, and our team gained immense clarity on service performance.
Sarah
Our production error budgets are now managed systematically using the frameworks learned here. The constant tension between our development and operations groups was successfully resolved, driving immense operational confidence.
Carlos
A major cloud infrastructure failure was resolved smoothly last week because our team followed the precise Incident Command structure outlined in this training. The incident response process became incredibly organized.
Deepak
Operational toil within our cloud platform squad was successfully audited and reduced by forty percent. Engineering time was freed up significantly, allowing us to focus entirely on valuable infrastructure automation.
Elena
Transitioning from a senior infrastructure engineering position into an operational management role was made simple. Deep career clarity was achieved, giving me the tools needed to lead distributed platform teams effectively.
Conclusion
The Certified Site Reliability Manager credential offers a clear, highly effective framework for managing production systems stably in a fast-paced technology market. By moving away from reactive firefighting and embracing metrics-driven site reliability principles, technical leaders can protect system uptime while supporting fast software delivery. Investing time into this certification pathway builds long-term career resilience, transforming technical professionals into valuable strategic leaders who can guide modern enterprises through complex infrastructure challenges.
Top comments (0)